
[뉴스로드] AI허브에서 개인정보가 유출된 것으로 <뉴스로드> 취재 결과 확인됐다. 지난 2월과 5월에 이어 세 번째다. 국민들의 개인정보가 담긴 AI학습용데이터셋이 민간기업 챗봇 서비스 고도화에 활용되고 있지만, 정부는 개인정보 보호를 뒤로 한 채 ‘데이터댐’ 쌓기에 급급하다.
AI허브는 과학기술정보통신부 산하 한국지능정보사회진흥원(NIA)이 운영하는 AI학습용데이터셋 플랫폼이다. AI학습용데이터는 챗봇·영상·헬스케어·자율주행 등 산업 전반의 AI 고도화에 활용한다.
정부는 2017년부터 구축한 데이터셋을 AI허브를 통해 제공하고 있다. 2025년까지 예산 2조5000억 원을 투입, 데이터셋 1300종을 보관하는 데이터댐을 쌓고 민간에 무료로 개방해 AI산업을 활성화하겠다는 취지다. 정부가 추진하는 ‘디지털뉴딜’ 핵심 사업이기도 하다.
문제는 데이터셋들의 품질이다. 주체가 누군지 알아 볼 수 있는 개인정보가 섞여 있거나, 가명처리(개인정보를 식별할 수 없도록 하는 작업)가 미흡해 IT기업들이 자사 AI 고도화에 활용하기가 어려운 상황이다.
◇AI허브 개인정보 유출, 정부판 ‘이루다 사건’ 우려
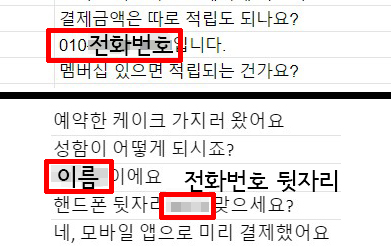
<뉴스로드>는 이달 AI허브 내 데이터셋 193종 가운데 약 10종을 무작위로 선정해 품질을 검토했다. 그 결과 자연어 분야 데이터셋인 ‘소상공인 고객 주문 질의-응답 텍스트’와‘한국어 대화’에서 국민들의 이름과 휴대전화번호 등을 발견했다.
소상공인 질의응답 텍스트는 롯데그룹 계열사 롯데정보통신이 구축한 데이터셋이다. 상점에서의 점원과 고객간 대화 녹취를 텍스트로 옮겨 적은 데이터다. 이 데이터에서는 010으로 시작하는 실존하는 휴대전화번호 3건을 확인했다.
한국어 대화 데이터셋에는 공공기관·식당·학원·숙박업소 등에서의 공무원-민원인, 점원-고객 간 대화 상황이 담겨 있다. 여기서는 가명처리가 안된 이름과 전화번호 1쌍, 별도 이름 1건을 찾았다.
한국어 대화 데이터셋의 경우 2019년 5월부터 지난해 2월까지 총 21개월간 국민들의 이름·생년월일·주소·전화번호·차량번호가 유출된 바 있다. 이후 두 차례 품질 보완을 진행했음에도 모든 개인정보를 완전히 비식별화하지 못한 것이다.
일련의 AI허브 데이터셋 개인정보 유출 사건들은 올해 초 화제를 모은 ‘이루다 사건’과 비슷한 양상을 띤다. 앞서 이루다 개발사 스캐터랩은 국민들의 카카오톡 대화 데이터셋에서 이름·휴대전화번호·주소 등 개인정보를 가명처리하지 않고 활용한 혐의 등으로 지난 4월 개인정보보호위원회로부터 과징금을 부과받은 바 있다.
AI허브 데이터셋 개인정보 유출 사건의 최대 쟁점은 구축기관들이 개인정보 주체들의 동의를 받았는가다. 이름과 전화번호 등 개인정보를 수집하면서 동의를 받지 않았다면 개인정보법 위반 소지가 있다.
◇NIA, 데이터셋 2종 전수조사 착수
<뉴스로드>는 해당 데이터셋들에서 개인정보를 확인한 뒤, 지난 7일 NIA에 ‘데이터셋 이용 신청 및 다운로드 차단’ 및 ‘이용자들에게 가명처리 미흡 사실 통지’ 등 조치할 것을 제언했다.
본지가 이 같은 조치를 요청한 까닭은 챗봇을 통한 개인정보 유출을 방지하기 위해서다. 해당 데이터셋들은 AI 기반 챗봇 고도화 목적으로 구축됐다. 이에 챗봇 개발사의 개인정보 필터링 기술 역량이 부족할 경우, 챗봇이 이용자들과의 대화에서 개인정보를 유출할 위험이 있다.
챗봇 개발사들에게는 이미 개인정보가 유출된 상황이다. 따라서 개발사들이 해당 데이터셋들을 폐기해야 더 큰 피해를 예방할 수 있다.
NIA는 본지의 제언사항을 8일 이행하고 전수조사 및 가명처리 작업에 착수했다. 이에 현재는 해당 데이터셋들을 AI허브에서 다운로드 불가하다.
◇AI학습용데이터, 개인정보 보호·활용도 높이려면?
본지에서 품질을 검토한 데이터셋은 전체 데이터셋 중 일부에 불과하다. 소상공인 질의응답과 한국어 대화 데이터셋 안에도 기자가 발견하지 못한 개인정보가 더 존재할 가능성도 있다.
이에 지금도 AI허브에서 개인정보 보호가 제대로 이뤄지고 있는지는 안심할 수 없는 상황이다. 자연어·음성 및 안면인식 등 개인정보가 포함됐을 개연성이 있는 모든 데이터셋에 대한 전수조사가 시급한 이유다.
또한 과기정통부와 NIA가 지난 2월 발간한 ‘AI학습용데이터 데이터셋 구축 안내서’를 IT기업들이 반드시 숙지하고 데이터셋을 구축할 수 있도록 의무화하는 방안도 필요해 보인다.
현재 AI허브 내 일부 자연어 데이터셋은 개인정보 정제 기준이 일률적이지 않고, ‘#전화번호#’ ‘010-1234-5678’ ‘010-0000-0000’ 등 과 같은 형태로 혼용되고 있다. 이처럼 정제 기준이 통일되지 않을 경우, IT기업들의 데이터셋 활용도가 떨어지는 문제가 있다.
NIA 관계자는 이번 개인정보 유출 사건에 대해 지난 9일 <뉴스로드>와의 서면 인터뷰에서 “소상공인 질의응답 텍스트는 공개 전에 개인정보처리 전문기관을 통해 익명처리 작업을 시행했지만, 기술적 한계와 검사 인력의 실수로 일부 누락됐다”고 설명했다.
이 관계자는 이어 “AI허브를 통해 데이터를 제공받은 이용자들을 대상으로 해당 데이터에 개인정보가 포함된 사실을 공지했고, 사용 중지 및 보유 중인 모든 저장기기에서 데이터 폐기를 요청했다”고 말했다.
그러면서 “해당 데이터에 대한 전수조사를 시행하고 일부 누락된 개인정보 비식별 작업을 진행할 예정이며, 보완 조치가 완료된 뒤 다운로드 서비스를 재개할 예정”이라고 덧붙였다.
이 관계자는 끝으로 “더욱 철저한 데이터 검증과 품질관리를 통해 유사한 문제들이 재발하지 않고, 좋은 품질의 데이터를 제공하기 위해 노력하겠다”고 말했다.