
[뉴스로드] 정부가 데이터댐을 부실 구축한 기업들에게 정기적인 품질 검증을 요구하기로 했다. 향후 다른 데이터댐 사업에 해당 기업들의 입찰을 제한하는 등 불이익을 주는 방안도 검토 중이다.
◇’데이터댐’에서 새어나가는 국민 개인정보
데이터댐이란 AI학습용데이터를 축적하는 국책사업을 일컫는다. 해당 데이터는 사물인식·안면인식·챗봇·번역 등 AI 기반 서비스 개발에 활용된다. 과학기술정보통신부와 산하기관 한국지능정보사회진흥원(NIA)이 주도하는 디지털뉴딜 핵심 사업들 가운데 하나다.
정부는 2017년부터 용역을 통해 구축한 AI학습용데이터를 플랫폼 ‘AI허브’에서 제공하고 있다. 올해 문제가 확인된 데이터는 자연어 분야의 ‘소상공인 고객 주문 질의-응답 텍스트’와 ‘한국어 대화’ 등 2종이다.
자연어 데이터는 주로 챗봇 개발에 쓰인다. 공공기관·식당·학원·숙박업소 등에서의 공무원-민원인, 직원-고객간 대화 문장이 적혀 있다. 챗봇이 상담 시 예상되는 상황에 대처할 수 있도록 고도화하는 데 필요한 데이터다.
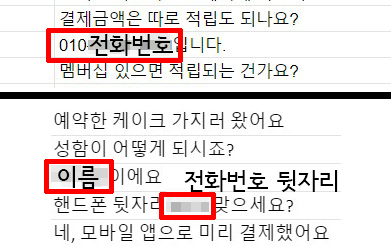
문제는 해당 데이터들에 국민들의 개인정보가 담겨 있었다는 것이다. 소상공인 질의응답에는 휴대전화번호, 한국어 대화의 경우 이름·생년월일·주소·전화번호·차량번호 등이 포함됐다. <뉴스로드>가 파악한 개인정보 유출 건수는 수십 건 규모지만 그보다 더 많을 가능성이 높다.
개인정보가 유출된 원인은 크게 2가지다. 첫째는 데이터 구축 인력들이 대화 문장에서 실존하는 이름과 전화번호 등을 사용한 것이다. 이에 대해 과기정통부 측은 “실제로 사용되지 않는 전화번호를 구축 인력들이 지어낸 것”이라고 해명하지만 이는 사실관계와 다르다.
둘째는 데이터를 구축한 기업들이 개인정보를 비식별화하지 않은 것이다. 데이터들에 속한 개인정보가 실존하는 정보라도, 가명·익명처리 했다면 막을 수 있는 사건이었다.
해당 데이터들은 이미 챗봇 개발에 활용되고 있어 2차 피해 우려가 존재한다. NIA에 따르면 2019년부터 올해 8월까지 AI허브에서 접수한 소상공인 질의응답 데이터와 한국어 대화 데이터 활용신청 건수는 각각 82건, 5085건이다.
◇AI학습용데이터 속 개인정보, 대기업·공공기관도 못걸러내

해당 AI학습용데이터들을 구축한 기관이 대기업 계열사와 공공기관이라는 점은 2차 피해 가능성을 더한다. 국내 최고 수준의 AI학습용데이터 전문성을 갖춘 기관들도 놓친 개인정보를, 중소 챗봇 개발사들이 찾기란 쉽지 않은 일이다.
소상공인 질의응답 텍스트는 롯데그룹 계열사 롯데정보통신, 한국어 대화는 한국과학기술정보연구원이 주도해 구축했다. 특히 롯데정보통신은 국내 5곳뿐인 민간 가명정보 결합기관들 가운데 1곳이다.
NIA에 따르면 현재까지 소상공인 질의응답 텍스트는 한 차례, 한국어 대화는 세 차례 이상의 개인정보 전수조사가 이뤄졌다. 여러 번 검수를 거쳤지만, 데이터 품질을 신뢰할 수 없는 이유다. 구축기관들은 현재도 추가 검수를 진행 중이지만, 이번에도 개인정보가 남아 있을 가능성은 배제할 수 없다.
NIA는 지속적으로 품질을 검증해 개인정보 유출을 막겠다는 계획이다. NIA는 지난 22일 <뉴스로드>와의 서면 인터뷰에서 “해당 기관들에 정기적으로 검증 및 보완을 요구해 데이터 제작을 끝까지 책임지도록 할 예정”이라고 밝혔다. 더불어 향후 데이터댐 사업 입찰을 제한하는 등 불이익을 주는 방안도 검토 중이다.
한편 정부는 AI학습용데이터 구축 예산으로 올해와 지난해 총 5850억 원을 편성했다. 내년에는 6732억 원을 배정했다. 정부는 2025년까지 예산 2조5000억 원을 투입해 데이터 1300종을 구축할 예정이다.
뉴스로드 김윤진 기자psnalism@gmail.com