[뉴스로드] 2021년 국회 국정감사 일정이 막바지에 이르고 있다. ‘데이터댐’ 현안을 다룬 과학기술정보방송통신위원회 국정감사는 지난 21일 마무리됐다. 정부의 데이터댐 사업 경과를 집중보도 중인 <뉴스로드>는 이번 국정감사에서 논의된 현안들을 되짚어봤다.
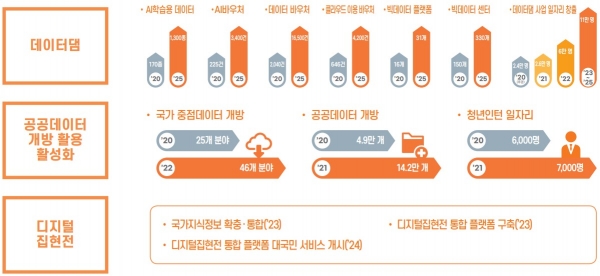
데이터댐이란 정부가 생산하거나 용역을 통해 구축하는 데이터를 축적하는 사업을 일컫는다. ▲중앙정부와 지방정부의 실태조사·통계 등 ‘공공데이터’ ▲사물인식·안면인식·챗봇·번역 등 AI산업에 활용하는 ‘AI학습용데이터’ ▲2024년 오픈 예정인 지식 플랫폼 ‘디지털집현전’ 등이 여기에 해당한다.
데이터댐은 범정부 한국판뉴딜 4대 정책 가운데 디지털뉴딜의 핵심 사업이다. 내년 예산은 18조6109억 원이며, 데이터댐 사업에는 1조4642억 원이 편성됐다.
정부는 데이터를 특성별로 나눠 제공하기 위해 플랫폼을 만들고 있다. 공공데이터는 ‘공공데이터포털’, AI학습용데이터는 ‘AI허브’, 논문과 강좌, 기타 학습자료는 ‘디지털집현전’으로 모은다. 공공데이터포털과 AI허브는 이미 서비스를 시작했다.
◇국회, ‘데이터댐’ 사업 수도권 편중 지적

현재 국회가 주목하고 있는 데이터댐의 가장 큰 문제는 ‘일자리’와 ‘데이터 품질’이다.
지난 8일 열린 국회 과방위 국정감사에서 의원들은 예산이 수도권에 쏠리는 현상을 조명했다. 더불어민주당 변재일 의원은 “데이터댐 구축 사업 예산의 71%가 수도권에 몰려 있다”며 “사업 참여를 희망한 기업은 수도권과 그 외 지역 5대5 비율이지만, 결과적으로는 수도권 중심으로 사업이 진행되고 있다”고 말했다.
국민의힘 홍석준 의원은 “AI학습용데이터 사업 수행업체들을 지역별로 보면 수도권이 366곳으로 압도적으로 많고, 나머지 영남·호남 지역 등은 미비하다”며 “데이터라벨링 같은 단순 아르바이트 일자리조차 수도권에만 있으면 그 외 지역에서 허탈감이 클 것”이라고 덧붙였다.
데이터라벨링은 사물인식이나 챗봇 등 AI 고도화에 필요한 자원을 구축하는 업무들을 아우른다. 데이터라벨링 일자리는 대부분 건당 보수를 받는 크라우드소싱(대중 참여) 형태다. 이는 의원들이 ‘단순 아르바이트 일자리’라고 지적하는 이유다.
국회에서는 데이터라벨러들의 일자리를 안정시키고 전문성을 높일 필요가 있다는 의견이 나온다.
국민의힘 김영식 의원이 과학기술정보통신부로부터 받아 지난 24일 공개한 자료에 따르면, 정부가 지난해 9월부터 올해 8월까지 창출한 AI학습용데이터 관련 일자리는 5만3080개였다. 이 중 단기 일자리인 데이터라벨링은 4만552개(76.4%)에 달했다.
데이터라벨러들은 이 기간 월평균 60.5시간 근로하는 데 그쳤다. 이 가운데 2만8109명(69.3%)은 보수가 50만 원 미만이었다. 200만 원 미만으로 넓혀보면 3만6589명(90.2%)까지 늘어난다. 파트타임 일자리인 탓에 대체로 법정근로시간 월 209시간에 못미친다.
◇‘수요 없는데 공급’ 데이터댐 쌓기 급급한 정부
2021년 국회 국정감사에서는 공공데이터·AI학습용데이터 수요 및 품질 문제도 거론됐다. 국민의힘 홍석준 의원은 지난 1일 열린 국정감사에서 활용이 어려운 데이터가 많다며 개선을 촉구했다.
당시 홍 의원은 “질보다 양에 치중해 수요자 중심으로 구축되지 않는다”며 “뿐만 아니라 오래된 데이터는 업데이트도 안되고, 활용할 수 없는 PDF·HWP 확장자 파일이 많아 오픈포맷 전환이 필요하다”고 강조했다.
데이터 품질이 낮은 원인이 구축 인력들의 전문성에 있다는 비판도 제기했다. 홍 의원은 “1~2시간에 불과한 교육을 받은 단기 아르바이트에 의해 AI학습용데이터가 구축되고 있어 품질을 신뢰할 수 없다”고 지적했다.
정부는 고용불안 해소와 수요자 중심 데이터 구축에 노력하겠다는 입장이다. 데이터댐 주무부처인 행정안전부·과학기술정보통신부·한국지능정보사회진흥원은 ‘공공데이터 일경험 수련생’과 ‘AI학습용데이터 라벨링 교육’ 등을 통해 국민들에게 일경험을 제공하고 전문가를 양성하고 있다.
공공데이터 일경험 수련생으로 참여하는 청년들은 정부부처에 단기 소속돼 공공데이터 개방 업무를 맡는다. 일경험 수련생 사업은 매년 진행되고 있다. 지난해까지는 ‘공공데이터 청년인턴’이라는 명칭이었다.
AI학습용데이터 라벨링 교육은 지난 8월 24일부터 진행 중이다. 데이터라벨러들이 IT업계에서 경력을 이어갈 수 있도록 심화교육을 제공한다. 이 밖에 정부는 ‘지역 특화 과제’를 발굴하면서 예산 수도권 편중 문제 해소에도 나서고 있다.
한편 정부가 공공데이터포털을 통해 개방 중인 공공데이터는 26일 기준 6만4120개에 달한다. 이를 민간이 활용한 사례는 상업·교육·연구 등 용도를 모두 포함하면 지난달 기준 3000만 건에 달한다. 정부는 개방 공공데이터 수를 14만2000개까지 늘릴 방침이다.
AI학습용데이터의 경우 현재 190여 종에서 내년 360종으로 확충한다. 디지털뉴딜 5개년 계획이 끝나는 2025년까지는 1300종을 확보할 예정이다.
뉴스로드 김윤진 기자psnalism@gmail.com