[뉴스로드] 정부가 AI 학습용 데이터 구축사업에서 크라우드 소싱 방식을 우대한다. 지난해 질 낮은 일자리라는 지적을 받았던 만큼, 올해는 양질의 일자리 창출에 기여할 수 있을지 관심이다.
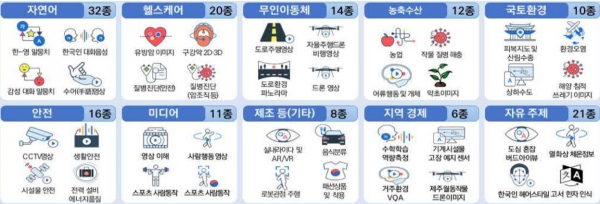
한국지능정보사회진흥원(NIA)은 ‘2021 AI 학습용 데이터 구축사업’ 계획을 지난 3일 발표했다. 이번 사업은 지정공모 72개, 품목지정 16개, 자유공모 4개 등으로 나뉜다. 예산 규모는 지난해와 동일한 2925억 원 규모다. 사업별로 최소 19억 원에서 많게는 76억 원까지 배정된다.
AI 학습용 데이터 구축사업 예산은 지난해부터 규모가 대폭 늘었다. 2019년까지는 연 50억 원 수준이었지만, 정부가 ‘데이터댐’으로 불리는 AI 학습용 데이터·공공데이터 축적을 디지털뉴딜 핵심으로 강조하면서 규모가 급격히 커졌다.
AI 학습용 데이터는 사물인식·안면인식·챗봇·번역 등 다양한 AI 기반 서비스에 필요한 자원이다. 하지만 구축에 많은 비용과 시간이 소요돼 스타트업이 직접 투자하는 데는 한계가 있다. 이에 정부가 적극적인 지원책을 펴는 것이다.
사업 수행기관은 이달부터 선정을 시작해 오는 5월에 최종 결정된다. 수행기관들은 5월부터 AI 학습용 데이터 구축에 착수해, 연내 결과물을 제출해야 한다. 구축된 데이터는 향후 전국민 누구나 영리적으로 사용할 수 있도록 개방된다.
지정공모 분야는 크게 ▲음성·자연어 ▲비전(영상·사진) ▲헬스케어 ▲교통·물류 ▲농축수산 ▲재난·안전·환경 6개로 구분된다. 품목지정에서는 ▲지역사회 특화 과제 10개 ▲지정공모 각 분야 당 1개씩 자유주제로 수행할 수 있다. 자유공모의 경우 ▲지정 분야와 무관한 주제 4개를 선정한다.
이번 AI 학습용 데이터 구축사업에서 눈에 띄는 부분은 ‘크라우드 소싱’을 통한 일자리 창출 우대사항이 강화됐다는 것이다. 크라우드 소싱은 대중이 참여하는 사업을 의미한다. 여기에 참여하는 이들을 ‘크라우드 워커’라 부른다. 라벨링 업무 수행자들은 ‘AI 데이터 라벨러’로 칭하기도 한다.
크라우드 워커들은 ▲VQA(Visual Question Answering, 사진에서 텍스트를 추출하는 작업) ▲논문·도서 내용 요약 ▲메신저 대화내용 제공 ▲자율주행 AI 개선을 위한 신호등·표지판·차선·횡단보도 등 인지 작업 등 다양한 업무를 수행한다.
지난해 일각에서는 크라우드 소싱 작업이 전문성을 요하지 않고, 업무 난이도가 낮아 ‘질 낮은 일자리’ ‘단기 아르바이트’ ‘디지털 인형 눈알 붙이기’ ‘일자리 창출 실적을 위한 일회성 일자리’ 등 지적이 나왔다.
다만 정부가 크라우드 워커 처우 개선 의지를 보이고 있어, 올해는 달라질지 관심이다. NIA는 수행기관이 데이터 구축에 시공간 제한 없이 전국민이 참여 가능한 크라우드 소싱 방식을 채택하는 것을 우대한다.
먼저 올해 크라우드 워커들의 임금이 소폭 증가할 전망이다. NIA는 수행기관들에 크라우드 워커들의 작업당 단가를 전일근무(20일/8시간) 가정 시 최저임금 이상 지급하도록 요구한다.
‘일자리’로 인정하는 기준도 구체화된다. 최소 3개월 이상(60시간 이상/월) 사업에 참여한 크라우드 워커에 한해 일자리 창출로 인정된다.
또 크라우드 워커들이 장기적으로 근로할 수 있는 방안도 마련됐다. 구축사업 수행기관은 크라우드 워커들의 교육 및 경력개발 지원책, 그리고 이들의 권익을 보호하기 위한 계획도 제시해야 한다.

한편 지난달 AI 학습용 데이터를 망라한 웹사이트인 ‘AI 허브’에서는, 2019년 1월 크라우드 워커들이 구축한 데이터에서 국민들의 개인정보가 유출되는 사건이 발생했다. 당시부터 지난달까지 21개월 간 국민들의 이름·전화번호·생년월일·주소 등이 유출됐던 것이다.
이는 크라우드 워커들이 실존하는 개인정보를 당사자 동의 없이 무단으로 도용해, AI 학습용 텍스트 데이터에 기재한 게 단초가 됐다. 과학기술정보통신부·NIA 등 AI 학습용 데이터 구축사업 담당기관은 크라우드 워커의 처우 개선뿐 아니라, 개인정보 유출 방지를 위한 교육 및 데이터 검수에도 신경 쓰는 노력이 필요해 보인다.