
[뉴스로드] 정부는 데이터댐 구축을 위해 올해 총 3300억 원을 ‘AI 학습용 데이터 사업’에 배정했다. 데이터댐은 국가가 주도하는 디지털뉴딜 핵심 사업이다.
최근 과학기술정보통신부는 AI 학습용 데이터 사업으로 2만2000여 개 일자리를 창출했다고 발표했다. 또 일자리 참여자들은 향후 IT업계 전문인력으로 성장해 나갈 것이라고 밝혔다.
<뉴스로드>는 정부가 창출한 일자리 참여자들이 적절한 처우를 받고 있는지, 전망은 어떤지 알아보기 위해 데이터댐 구축을 직접 체험해봤다.
AI 학습용 데이터 사업은 대중이 참여하는 ‘크라우드소싱’ 형태로 진행된다. 남녀노소가 언제 어디서든 자투리 시간을 내서 할 수 있을 정도로 쉽다는 게 특징이다.
다만 기자가 사업에 참여해 본 결과, 참여자들이 이를 통해 AI·데이터 전문지식을 기를 수 있을지는 의문이었다. 임금이나 고용안정 측면에서도 양질의 일자리로 보기에는 어려움이 있었다.
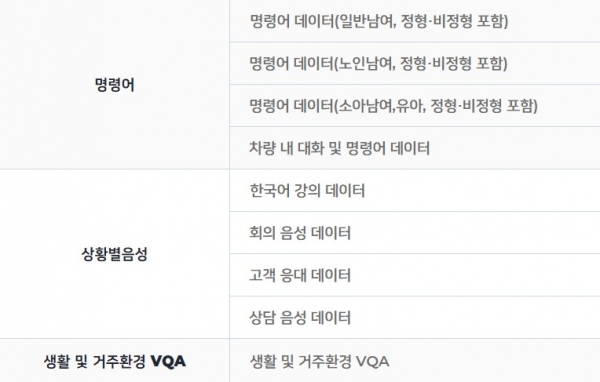
AI 학습용 데이터 사업은 과기정통부 산하 ‘AI허브’ 웹사이트에서 참여할 수 있다. 모집 중인 업무는 ▲사진에서 텍스트를 추출하는 ‘VQA(Visual Question Answering)’ ▲논문·도서 내용 요약 작업 ▲메신저·SNS 등 사적 대화내역 제공 ▲자율주행 AI 개선을 위한 신호등·표지판·차선·횡단보도 인지 작업 ▲음식물 사진에 칼로리 기입 작업 등 분야별로 다양했다.
참여 방법은 간단하다. 정부가 선정한 민간사업자들의 웹사이트에 가입한 뒤, 원하는 업무를 고르면 된다. 특별한 자격을 요구하지 않으며, 간단한 업무 가이드를 이해할 수 있기만 하면 된다.
기자는 민간사업자 ‘라벨온’이 모집 중인 ‘생활 및 거주환경 VQA’ 데이터 구축을 체험해봤다. 사진을 단서로 유추할 수 있는 질문과 답변을 생성하는 업무다.
작업가이드는 다음 사진과 같다.

가이드를 읽고 이해하는 데는 3분이 채 걸리지 않았다. 기본적인 국어 지식만 있다면 이해할 수준이었다. 다음으로는 본격적으로 작업을 시작했다.
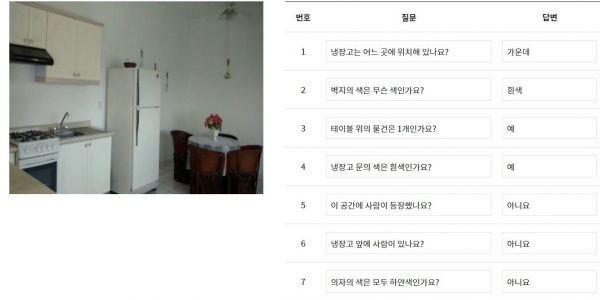
작업창에서는 한 장의 사진과 일곱 문항의 빈칸이 제시됐다. 가이드에 따라 질문과 답변칸에는 사진 속에 ‘냉장고는 어느 곳에 위치해 있나’ ‘벽지의 색은 무슨 색인가’ 등을 생각해서 기입했다. 사진 속 한정적인 단서로 중복되지 않는 질문을 만들어야 하며, 한 문항 당 작업 시간은 1분 정도 소요됐다.
작업을 완료한 결과, 수익은 420원이었다. 한 문항 당 60원의 대가가 주어졌다. 한 사람이 이렇게 작업할 수 있는 문항은 총 20문항이다. 문항 당 1분이 소요된다고 가정하면 일일 최대 1200원이 수중에 들어오는 셈이다. 시급으로 계산하면 1200원X3=3600원으로 2020년 최저시급인 8590원의 절반에도 못 미친다.

AI허브에는 작업 당 700원이 지급되는 업무도 있었다. 메신저·SNS 등 사적 대화내역을 업체에게 제공하는 일이었다. 비교적 수당이 높은 까닭은 작업 난이도보다는 개인정보를 제공해야 하기 때문으로 보인다.
이 역시 VQA처럼 간단한 작업가이드를 숙지하면 참여할 수 있다. 참여자 본인이 지인들과 나눈 카카오톡 대화 내용을 이름·주소·전화번호 등 개인을 특정할 수 있는 정보를 제거한 뒤 송고하면 끝이다. 작업 총량은 1만 건으로 제한된다.
과기정통부에 따르면 모든 AI 학습용 데이터 구축 업무는 남녀노소 수행할 수 있을 정도로 어렵지 않다. 과기정통부는 이 같은 사업을 통해 ‘경력단절 여성’ ‘장애인’ ‘소년소녀가정’ ‘은퇴자’ 등에 일자리 참여 기회를 제공하고 있다고 설명한다.
그러나 AI 학습용 데이터 구축 업무는 예산이 소진되면 참여도 중단되는 사업이다. 또한 일일 작업량에도 한계가 있고, 개인정보를 제공하지 않는 일반 업무는 대가가 낮다. 이 경험으로 취업을 위한 전문지식을 얻기도 어렵다. 즉, 경력단절자의 사회 재진출이나 장기 미취업자 문제도 근본적으로 해결할 수 없는 것이다.
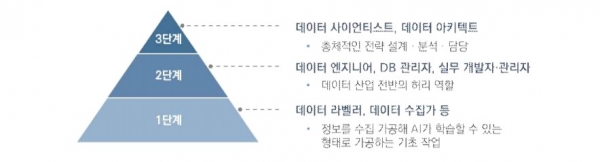
과기정통부·행정안전부 산하 한국정보화진흥원 문용식 원장은 17일 칼럼을 통해 “AI 데이터 구축 사업이 단기 알바성의 질 낮은 일자리만 양산하는 ‘디지털 인형 눈알 붙이기 사업’이라는 비판이 있다”면서 “처음엔 단순한 데이터 가공 업무로 데이터의 세계에 입문했다가 점차 전문인력으로 성장해 갈 것”이라고 말했다.
하지만 당국은 아직 AI 학습용 데이터 구축 참여자들에 대한 취업 지원·직무 교육 등 전반적인 로드맵을 발표하지 않은 상황이다. 당국은 ‘데이터댐’ 공사를 위해 취업 취약계층에게 희생만 요구하고 있지는 않은지 돌이켜 볼 필요가 있어 보인다.